文章詳情頁
python - 標簽樹的下行遍歷如何跳過第一個標簽
瀏覽:143日期:2022-08-08 11:07:17
問題描述
爬取網頁用下行遍歷的找出了我要的標簽,但第一個的內容我是不要的用.children好像無法跳出第一個標簽
for tr in soup.find(id='endText').children: if tr.string is not None:a = tr.string
網頁的內容:
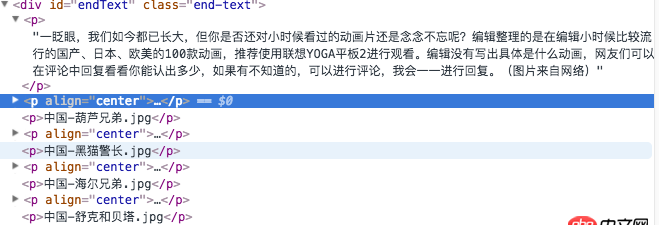 原鏈接:http://digi.163.com/14/1115/0...
原鏈接:http://digi.163.com/14/1115/0...
問題解答
回答1:p_list = list(soup.find(id='endText').find_all(’p’))for p in p_list[1:]: text = p.get_text() img = p.find('img') if img:print img.get(’src’) if text:print text
相關文章:
1. 如何解決Centos下Docker服務啟動無響應,且輸入docker命令無響應?2. 我在centos容器里安裝docker,也就是在容器里安裝容器,報錯了?3. objective-c - IOS 分享到微信 提示 應用消息數據錯誤4. android - 使用百度sdk調用SDKInitializer.initialize(this)時報錯?5. javascript - 微信h5發送圖文信息,部分設備點擊“發送”按鈕時沒反應,問題較難重現,如何能找到可能存在問題的點?6. javascript - 音樂播放器-圖片旋轉7. android - 為 AppBarLayout 設置的背景圖片 TransitionDrawable 為什么只在第一次打開的時候有效?8. javascript - js中遞歸與for循環同時發生的時候,代碼的執行順序是怎樣的?9. MySQL timestamp的默認值怎么設置?10. docker 17.03 怎么配置 registry mirror ?
排行榜
 網公網安備
網公網安備