文章詳情頁(yè)
python - scrapy運(yùn)行爬蟲一打開就關(guān)閉了沒有爬取到數(shù)據(jù)是什么原因
瀏覽:93日期:2022-08-05 15:09:38
問題描述
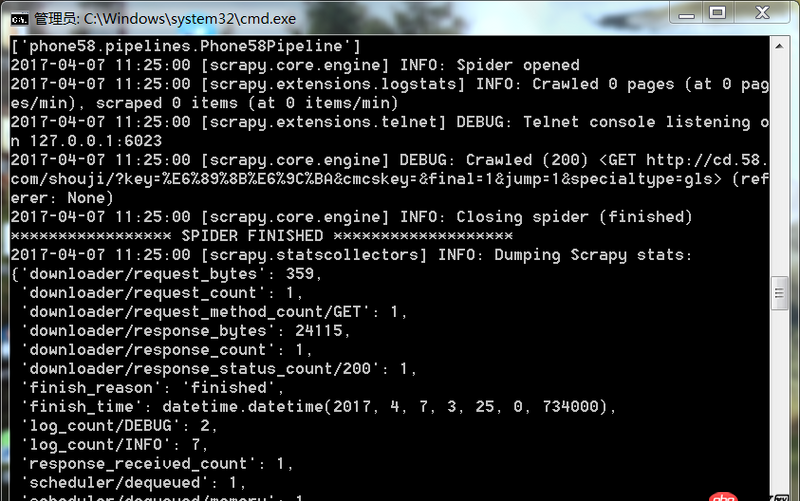
爬蟲運(yùn)行遇到如此問題要怎么解決
問題解答
回答1:很可能是你的爬取規(guī)則出錯(cuò),也就是說你的spider代碼里面的xpath(或者其他解析工具)的規(guī)則錯(cuò)誤。導(dǎo)致沒爬取到。你可以把網(wǎng)址print出來(lái),看看是不是[]
相關(guān)文章:
1. 在應(yīng)用配置文件 app.php 中找不到’route_check_cache’配置項(xiàng)2. html按鍵開關(guān)如何提交我想需要的值到數(shù)據(jù)庫(kù)3. HTML 5輸入框只能輸入漢字、字母、數(shù)字、標(biāo)點(diǎn)符號(hào)?正則如何寫?4. javascript - 請(qǐng)教如何獲取百度貼吧新增的兩個(gè)加密參數(shù)5. gvim - 誰(shuí)有vim里CSS的Indent文件, 能縮進(jìn)@media里面的6. 跟著課件一模一樣的操作使用tp6,出現(xiàn)了錯(cuò)誤7. PHP類屬性聲明?8. javascript - JS請(qǐng)求報(bào)錯(cuò):Unexpected token T in JSON at position 09. objective-c - ios 怎么實(shí)現(xiàn)微信聯(lián)系列表 最好是swift10. java - 安卓接入微信登錄,onCreate不會(huì)執(zhí)行
排行榜
熱門標(biāo)簽
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備